
Continuing where I left off in part 1, a list of things I had to struggled with when I switched from Django to MEAN.
Should I embrace Mongo or stick with Postgre/MySQL?
There's no right answer here, so I'll speak from experience. Thinking relational is what I'm used to and it's not trivial to make the shift to schemas that may actually encourage data duplication. At first I decided to stick with MySQL but I quickly switched to Mongo for a few reasons:
- There is no free SQL hosting service I felt like using. Heroku's free Postgre tier has a 4 hour monthly downtime which I couldn't stomach
- Clearly SQL is a road less traveled with Node/Express. There's a ton of documentation on Mongo integration and defacto standard tools to wrap it (mongoose, for example)
- I really wanted to put all the stuff I read about the pitfalls/benefits of document stores to practice. I knew only getting my hands dirty would illustrate the document paradigm for better and worse
To be honest, at first I used Mongo as a relational datastore - I simply converted tables to documents, with references between them. This was done under the incorrect understanding that embedded/sub documents declared with mongoose create seperate documents under the hood anyway. However, once I realized this wasn't the case I quickly switched the schema to hold everything relevant under a single document and things flew (code complexity wise, not performance wise). I had a much easier time accessing my data because the sort of queries I was doing just clicked with how the schema was laid out, and that is how everyone says you should base your schema design anyway.
Is there a place I can deploy my projects for free?
Here's what I use for my project:
- 1 Heroku dyno
- MongoLabs: I didn't use the Heroku addon rather signed up directly
- NewRelic addon: Checks uptime and keeps the dyno warmed up so that it won't take a few seconds to spin up if there's no traffic to it
- Logentries addon: Aggregates all logs into something that's easy to search and traverse. Free tier has acceptable log retention
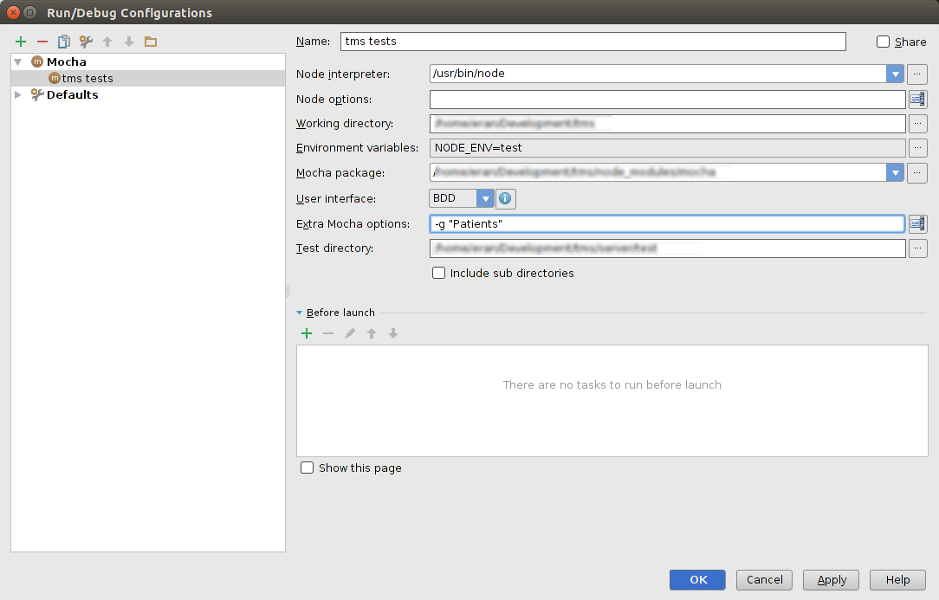
How do I choose which tests to run with Mocha and Webstorm?
Mocha supports selecting which tests to run by running it as:
mocha -g <test name>
Since this is grep-like, you can even pass it something partial - anything in the test name or description. This holds true to running Mocha tests from within Webstorm. Go to Run | Edit Configurations. Then in Extra Mocha options enter -g "
Modules/helpers I should use from day 1?
There are a billion really popular modules and that makes it difficult to decide which should be used early on. As you gain more and more experience you'll probably have a toolbelt of your go to modules, but choosing incorrectly at an early stage may sometimes mean you'll have to refactor a lot of ugly code that. Here are a few modules I think even test projects should include.
nodemon
A really useful tool to reload your Node service every time you change your code. Since I separate client from server code, I don't want the server to reload every time I change some frontend stuff, so I only instruct it to watch the /server the directory as such:
nodemon server/src/server.js --watch server
Where server/src/server.js is main Node module and server is the directory containg server code. Note that by entering:
rs
Into the console, you can force restart the server.
bower
Instead of pulling in frontend JavaScript modules manually (and managing their depenedencies), use bower to handle that. There are enough tutorials out there to explain how to work with bower, but note that you'll have to call bower install on postinstall to get Heroku to install the bower modules.
underscore
I was rather shocked just how inelegant JavaScript is compared to Python. Underscore helps that a bit by offering basic, common functions you would have had to implement yourself. Things like finding in an array, sort'ing, map'ing, etc.
Some promise module (Q / bluebird)
In most Node examples you will find that asynchronous callbacks are passed by supplying an anonymous function:
someAsyncCall(arg1, arg2, function(result) {
// do something, sometimes call another async call
}
At first this will seem rather neat, but you will then find yourself struggling with:
- Nested calls, making the code unreadable
- Parallelizing several async calls
- Error handling
You can use async for this, but there's a much more elegant solution which is Promises. If you've ever working with Python Twisted, they are equivalent to a deferred. Promises require quite a bit of practice and the syntax may be a bit odd initially but you're much better off learning this valuable tool before you write the bulk of your code than after.
How can I run Node locally and still be able to receive Webhook calls?
Lets say your backend code calls some service which needs some time to process the request. More often than not, the reply will be called via a Webhook (that is, usually POST that the service calls on your server in response to your request). This means you need to export an endpoint accessible from the internet. If you're a sane person, you will develop and deploy your code locally until it's ready for staging an production - which means you're behind a NAT ("firewall") of some sort.
You could go the port forwarding route but that's tedious and not always possible. Instead, I highly recommend using localtunnel.me. This awesome free service runs an agent on your machine which connects to the localtunnel.me servers and receives a unique, public URL (e.g. eran.localtunnel.me). Any request to this URL made from anywhere will be forwarded to the agent running on your machine.
When you run the agent, you tell it two things:
- The name of the URL you want (e.g. eran)
- The port to which to forward all requests the agent receives (namely, the port you run Node on)
lt --port 8080 --subdomain eran
In this case, I am asking for eran.localtunnel.me and running my Node application on port 8080. If a server executes a webhook and POSTs to eran.localtunnel.me/some/sub/path it will effectively hit my Node application at /some/sub/path. Very cool.
How can I test endpoints that use an API, without hitting an external server?
Simply use nock. Nock lets you override outgoing requests (by instrumenting Node) so that you can both check validity of the request and tailor a response. Check out my payments tests and look for nock.
I use a service which produces government approved invoices called greeninvoice. In these tests, I check that the Node application crafts the correct request towards greeninvoice according to payment method (cash, cheque, transfer). Here's an excerpt of me telling nock to catch any outgoing requests to greeninvoice:
// expect invoice and check all parameters, including cash
nock('https://api.greeninvoice.co.il')
.post('/api/documents/add')
.reply(200, function(uri, requestBody)
{
invoice = getGreenInvoiceDataFromRequest(requestBody);
expect(invoice.params.doc_type).to.equal(320);
expect(invoice.params.client.name).to.equal(newPayment.transaction.invoice.recipient);
expect(invoice.params.income[0].price).to.equal(newPayment.sum);
expect(invoice.params.income[0].description).to.equal(newPayment.transaction.invoice.item);
expect(invoice.params.payment[0].type).to.equal(1);
expect(invoice.params.payment[0].amount).to.equal(newPayment.sum);
// return a response indicating success
return {'error_code': 0, data: {ticket_id: '8cdd2b30-417d-d994-a924-7ea690d0b9a3'}};
});